The Osiris Programming Language: Crafting a better runtime

Background
The key design goal of Osiris is to support embedded and Internet of Things (IoT) applications running on a number of different microcontroller families e.g. ARM Cortex-M3/M4 and AVR. We have been very busy over the last couple of months redesigning and reimplementing the Osiris runtime library and memory model in order to reduce the size of the compiled application binaries and their memory (RAM) footprint from that originally used by its Sun workstation-based predecessor Anubis. Although Anubis applications could run quite successfully on ARM Cortex-based boards, the challenge of dramatically reducing the size of Osiris applications and their memory footprint was raised when we were asked if Osiris could produce applications for the Intel MCS-51 (better known as the 8051/8052) family of 8 bit microcontrollers
Although the main focus of Osiris development has been for the 32 bit ARM Cortex-M series using the LLVM compiler toolkit, we have also been working in the background on a version for the modern 8 bit AVR microcontroller family using the C compiler backend. However, as the MCS-51 is still used extensively in large-volume production embedded systems we decided to take some time to seriously investigate the viability of Osiris on this platform. We weren't surprised that it would be challenging to leverage the 64KB code and separate 64KB RAM of the MCS-51's Harvard Architecture, but we were pleasantly surprised by the viability of our initial version - the Osiris runtime library code size is 16KB with options to reduce this further. The resulting MCS-51 runtime and memory model have provided some valuable learnings that we have also applied to the ARM Cortex-M runtime. I'll provide more information on the MCS-51 version in a later post, but for now I'll cover the new ARM Cortex-M memory model and runtime.
The fully block-structured nature of Osiris demands some sophisticated requirements of the runtime, over and above those required by languages like Java and C, which might not be immediately obvious. The primary requirement is the full implementation of closures necessary to support first-class procedures and nested functions. For example, in Java closures are known as lambda expressions and can only access enclosing constant (final) items. Since first-class procedures can be passed into and returned from other functions, all local variables of the procedure must accessible anywhere it can be called. At first glance, the function pointers found in C provide the same capability as Osiris first-class procedures and, in fact, they are used by the Osiris runtime as part of its first-class procedure support. However, it is the ability for first-class procedures to be nested and reference non-local variables that mandates the implementation of closures and differentiates them from the function pointers found in C.
Example
In the example below, inner() is a first class nested function that is returned by the enclosing outer() function. The interesting feature is that the magicNumber variable can be accessed and updated by inner(), even when it has been returned by the outer() function and assigned to another identifier (e.g. magicFunc). This is the same as accessing global variables within procedures in C/C++ or any of the other languages in the Algol family e.g. Pascal. However, the behaviour here is also similar to the use of a static variable within a C procedure, in that the value is preserved between successive calls of the function. For example, when outer() is called magicNumber is declared in its environment and is initialised to 5. The next time outer() is called a new environment is created and a new magicNumber is declared with the value 5. This is the same as for local procedure variables that are created on the stack in C/C++, except that in Osiris the lifetime of these variables is deterministic after the function returns i.e. they continue to exist until they are no longer referenced and can be deleted. I'll cover how the Osiris runtime performs memory management in a later post. For now, we can see that we have the concept of a chain of environments to support the fully block-structured nature of the language (nested functions, local class definitions within a procedure etc.), providing a powerful and consistent programming model.
# A function that returns another function which takes
# two integers as parameters and returns an integer
let outer = proc(->proc(int,int -> int))
begin
# A local variable to the outer() function that
# is also accessible to the inner() function
let magicNumber := 5
# A function that updates the variable 'magicNumber'
# and returns the result of a calculation using it
let inner = proc(int x,y -> int)
begin
# Update the variable in the enclosing scope
magicNumber := magicNumber + 1
# Return the result
x+magicNumber*y
end
# Return the inner() function declared above
inner
end
# Call outer() and assign the result, the inner() function,
# to the constant 'magicFunc'
let magicFunc = outer()
# Call 'magicFunc' and write the result (20)
write magicFunc(2,3)
# Call 'magicFunc' and write the result (23)
write magicFunc(2,3)
# Call 'magicFunc' and write the result (26)
write magicFunc(2,3)
If you are a familiar with JavaScript, the above code will look familiar - it's almost the same as how objects are declared. In fact, first-class procedures can be used to encapsulate and protect data in a similar manner to classes and, as we will see, Osiris uses an extension of the environment model to implement its OO model.
In the above example, although the value of magicNumber changes each time magicFunc is called, the size of its environment doesn't. This is true of all environments in Osiris and their size is calculated by the compiler. It is useful to think of environments as being the same as function stacks in C/C++ where the values of non-pointer / reference types e.g. int and float contribute to the stack's size, whereas those of pointer types e.g. char* don't (of course, the pointer itself does). Like C/C++ stacks, environments (and their enclosing non-pointer variables / constants) can be deleted after the function exits if they aren't referenced by a returned nested function.
Original Memory Model
The Anubis memory model is based around the concept of holders - structures that wrap all variables and constants to enable the runtime to support the language's orthogonal persistent programming features. They are an elegant solution to the problem of ensuring that all data items remain type-safe when shared between programs using the persistent store i.e. a real cannot be read back in as a bool. However, the holders add a significant memory overhead of 96 bits per item for basic types like an int and significantly more for vectors, as can be seen in the diagram below:
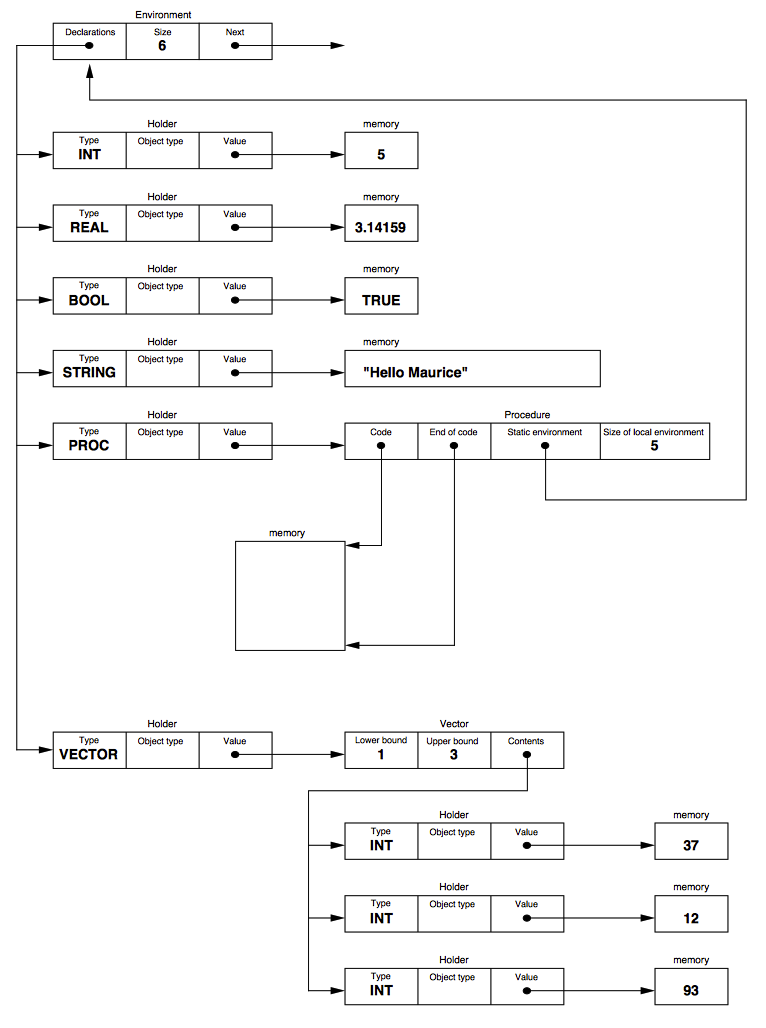
Figure 1 - Anubis Memory Model
Another interesting implementation feature that can be seen from the diagram is the Code and End of code pointers stored in the Procedure structure. These are used together to calculate the size of the procedure, excluding its environment, for storage in the persistent store. As no Anubis procedures use the underlying C stack for local variable definitions, the compiled procedure's size in memory is size=(End of code)-(Code) and this code block, plus the environment, can be saved to the persistent store. When a program needs to use a persistent procedure, a new holder is created, along with a procedure structure and a memory block for the binary procedure code, and the code is read in from the store. The procedure can now be called, and its respective environment created, as if it had been declared within the current program. In a similar manner, procedures could be loaded across a network connection, allowing programs to be updated remotely whilst they are running. As this is a feature we are working on for Osiris, we have retained this capability in the new memory model and we will return to the specifics of Osiris' dynamic update mechanism, including its security model, in a later post.
Whilst type information is always required at runtime for a persistent programming language, this isn't the case for production embedded systems and the Anubis model makes it more difficult for it to be removed when it isn't needed. Furthermore, the Anubis runtime doesn't allow identifier names to be stored in the binary for debugging support and these restrictions, plus the expanded memory footprint, led to the design of a new memory model for Osiris.
New Memory Model
The new Osiris memory model separates the type information from the item storage to allow it to be discarded for production embedded applications, saving a significant amount of memory as outlined above. Whilst the size might seem trivial for modern desktop and server machines, it becomes critical when the memory footprint of the device is measured in KB not GB. The new model also supports the storing of the identifier names to aid debugging and enhance Osiris' type introspection in the future:
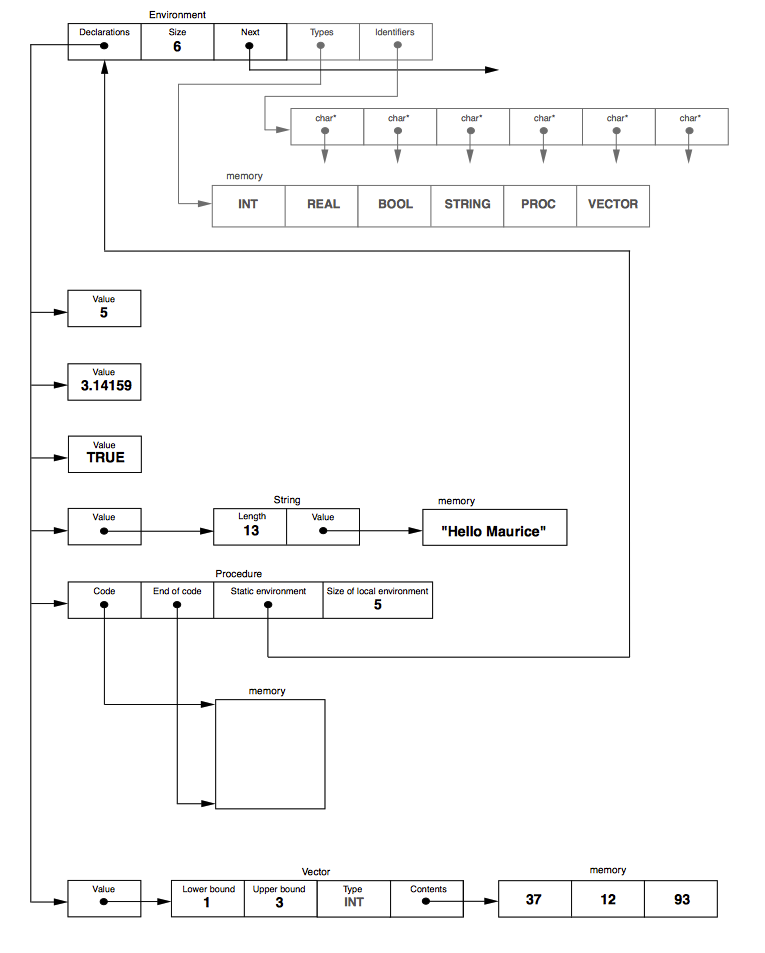
Figure 2 - Osiris Memory Model
The Types and Identifiers arrays are marked in grey on the diagram to indicate that they can be dropped from the binary to save memory. You might notice that the Next pointer isn't at the end of the struct as you would expect - in production mode, a different Environment structure can be used that only contains the Declarations, Size and Next fields but in both cases, the Next field is always 64 bits (on the ARM) from the start of the struct in memory. This makes it easier to write an optimised assembly language routine to iterate through the environment list without worrying about having to skip over the Types and Identifiers fields when the debugging information is included in the binary.
As can be seen from the diagram, Osiris now also has length-prefixed strings (like Pascal) allowing the use the faster memcmp and memcpy C library functions. The latter is optimised on the ARM and is significantly faster than strncpy. As Anubis/Osiris strings are immutable, having the pre-calculated length greatly increases performance - Osiris, unlike Anubis and C no longer has to chain through the string using strlen to calculate its length. Internally, the strings are still null-terminated and can be used anywhere a C string is used by either using the Value field of the structure or by adding 32 bits (on the ARM processor) to the Osiris string pointer to reference the null-terminated character array directly. On the MCS-51, the Length field is only 16 bits as there is little point supporting a string size of 4GB of when there is only ever a maximum of 64K of RAM available (discounting bank switching which has a maximum of 4MB). The Value fields and pointers in the environment will are also 16 bit to save memory, resulting in Osiris being a 16 bit language on the MCS-51 and 32 bit on the ARM and Intel x86.
The changes to the memory model and improved memory management have resulted in Osiris programs using 87% less RAM and are 10% faster than their Anubis equivalents. Furthermore, as the new Osiris runtime library is now 70% smaller than the original Anubis-based one, Osiris is perhaps one of the few truly Object-Oriented languages for embedded systems development, particularly on 8 bit microcontrollers like the MCS-51 and AVR.
We have further improvements planned to increase the performance of Osiris which we will cover in a later post, along with the generated C code (finally!)